Achieving Hyperscale Efficiency: A Step-by-Step Guide to Meta's AI Agent Platform
Introduction
At Meta, serving over 3 billion users means that even a 0.1% performance regression can translate into massive power drain. The Capacity Efficiency Program tackled this challenge by building a unified AI agent platform that automates the detection and resolution of performance issues at hyperscale. This guide breaks down how Meta engineered a self-sustaining efficiency engine that recovers hundreds of megawatts (MW) of power—enough for hundreds of thousands of homes—while freeing engineers from manual troubleshooting. The approach combines offensive (proactive optimizations) and defensive (regression detection) strategies, encoded into reusable AI skills. Follow these steps to understand how you can apply similar principles to your own large-scale infrastructure.

What You Need
- A hyperscale infrastructure with measurable resource usage (CPU, memory, power).
- Domain experts (senior efficiency engineers) with deep knowledge of performance tuning.
- An existing regression detection tool (like Meta's FBDetect) to identify performance drops.
- A unified tool interface that standardizes how agents interact with infrastructure components.
- AI/ML capabilities to build agents that can encode domain expertise and automate actions.
- A culture of offensive and defensive optimization—balancing proactive improvements with rapid fixes.
Step 1: Define Your Offense and Defense Strategy
Start by splitting your efficiency efforts into two complementary tracks. Offense involves proactively scanning for code changes that can make existing systems more efficient. Defense monitors production resource usage to catch regressions caused by new deployments. Meta formalized this dual approach: offense finds opportunities, defense detects issues that slip through. Without this clear separation, you risk focusing only on reactive fixes or only on speculative optimizations.
For offense, outline a process for identifying high-impact candidate changes (e.g., algorithm improvements, caching tweaks). For defense, implement a system that triggers alerts when key metrics (like CPU per request) deviate beyond a threshold. Meta’s FBDetect tool catches thousands of regressions weekly—this step is critical because even a small regression compounds across millions of servers.
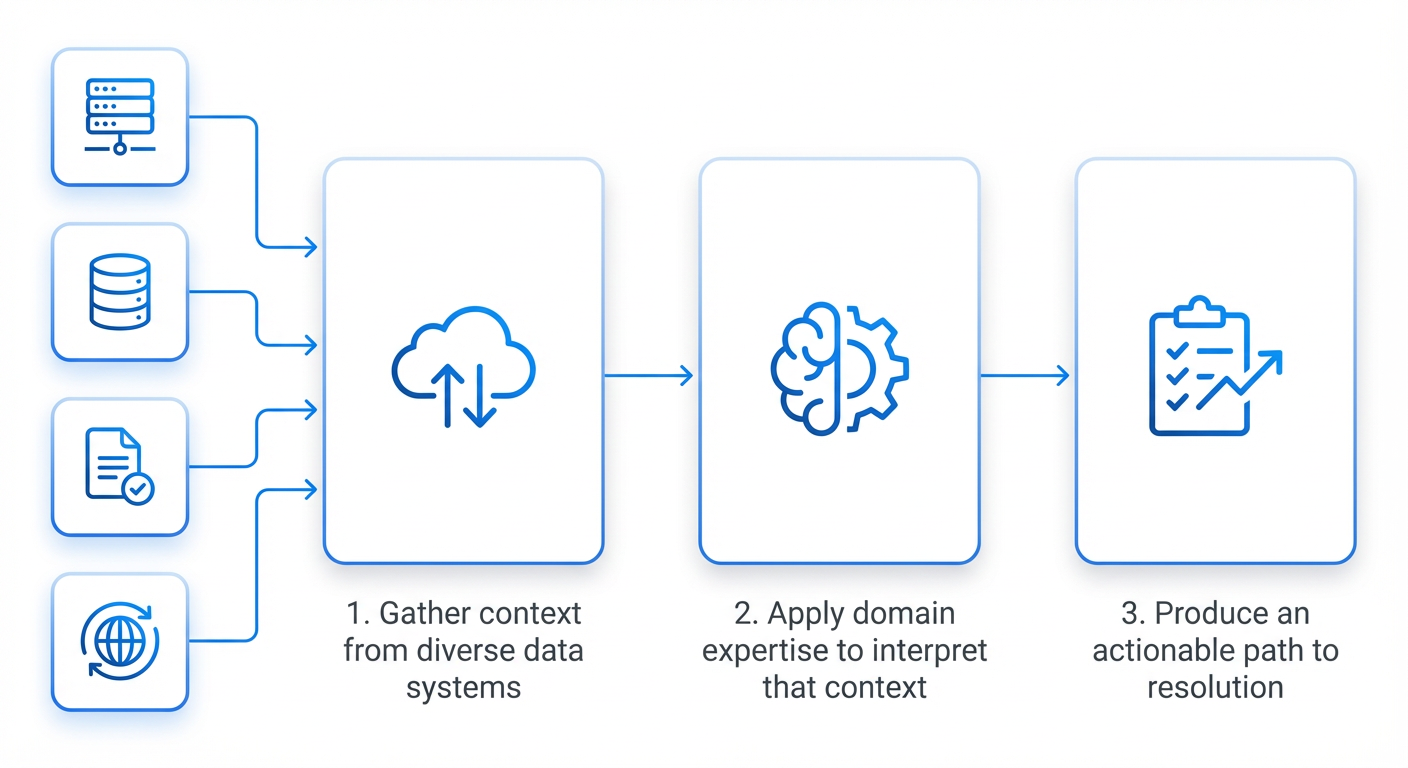
Step 2: Build a Unified AI Agent Platform
Create a platform that orchestrates AI agents with standardized interfaces. These agents should be able to access any tool or data source in your infrastructure (monitoring, logs, deployment systems). Meta's platform uses a “unified, standardized tool interface” so agents can act consistently regardless of the underlying system. This means defining common APIs for querying metrics, running A/B tests, or creating pull requests.
Each agent encodes encoded domain expertise—the knowledge of senior engineers about what causes performance issues and how to fix them. Break this expertise into reusable, composable skills. For example, a skill might be “analyze CPU usage patterns” or “generate a patch for inefficient loops.” Agents can combine these skills dynamically to investigate any regression or opportunity.
Step 3: Automate Regression Detection (Defense)
With your AI platform ready, automate the defensive side. Use your regression detection tool (like FBDetect) to feed alerts directly into the AI agent system. When a regression is identified, an agent automatically starts an investigation: it checks recent deployments, correlates metrics, and isolates the root cause to a specific pull request. Meta reports that this automation compresses roughly 10 hours of manual investigation into 30 minutes.
Set up the agent to not only find the cause but also propose a fix. Because the agent has encoded domain expertise, it can often recommend a code change that mitigates the regression. The agent then creates a ready-to-review pull request for human engineers. This speeds up resolution dramatically, reducing the number of megawatts wasted while the regression compounds across the fleet.
Step 4: Proactive Opportunity Resolution (Offense)
On the offensive side, deploy AI agents to continually search for efficiency opportunities. These agents scan codebases, analyze performance bottlenecks, and identify areas where minor changes can yield major power savings. Meta expanded this to more product areas every half-year, handling a growing volume of wins that engineers would never get to manually.
Your agents should be able to go from opportunity discovery to a ready-to-deploy pull request without human intervention. For example, an agent might spot a pattern of redundant database queries, then automatically rewrite the code to batch them. The output is a pull request with clear performance projections. This turns a workforce bottleneck into an automated pipeline—enabling your program to scale MW delivery without proportionally scaling headcount.
Step 5: Integrate and Iterate for Self-Sustainability
Combine offense and defense into a continuous cycle. When an agent fixes a regression (defense), that knowledge feeds back into the skill library. When an opportunity is resolved (offense), the agent learns from the outcome. Over time, the AI platform becomes a self-sustaining efficiency engine that handles the long tail of performance issues.
Meta’s end goal is exactly this: a system where AI handles the majority of findings, leaving engineers free to innovate on new products. Measure success by the recovery of power (hundreds of MW) and the reduction in manual engineering hours. Scale the platform to new product areas by encoding new domain knowledge as skills. This step is ongoing—the platform evolves as infrastructure changes.
Tips for Success
- Start with a strong baseline: Invest in a regression detection tool like FBDetect before building agents. You can’t fix what you can’t measure.
- Invest in domain expertise encoding: The most valuable part of your platform is the knowledge of senior engineers. Take time to extract heuristics and decision trees into reusable skill modules.
- Design for composability: Build skills that can be mixed and matched. A “read metric” skill plus a “compare performance” skill can solve many problems.
- Monitor and refine: Track how many issues are fully automated vs. requiring human intervention. Use that data to improve agent decision-making.
- Balance speed and safety: Automated pull requests are powerful but need guardrails. Implement approval gates for changes that affect critical paths.
- Scale gradually: Start with one product area, prove the model, then expand. Meta expands to more areas each half-year—a measured pace reduces risk.
By following these steps, you can build a platform that recovers megawatts of power, compresses hours of work into minutes, and lets your engineering team focus on innovation. Meta’s program is proof that when AI and domain expertise unite, hyperscale efficiency becomes a self-fulfilling prophecy.
Related Articles
- 5 Key Insights into Kubernetes v1.36's PSI Metrics Graduation
- Mastering Memory Control with BPF: A Practical How-To Guide
- Implementing HDMI 2.1 FRL Support in the AMDGPU Linux Driver: A Developer's Guide
- 10 Key Insights on Using DMA-Bufs for Read and Write Operations
- Rust-Powered Terminal Emulator 'Ratty' Introduces 3D Rat Cursor and GPU Rendering
- Mastering Your System PATH: A Step-by-Step Guide to Adding Directories
- Ubuntu 26.10 Has a Surprising Codename: Meet 'Stonking Stingray'
- Ratty: The Terminal Emulator That Thinks Outside the Box (and in 3D)