How Meta's Adaptive Ranking Model Revolutionizes LLM-Scale Ad Serving
Meta's cutting-edge Adaptive Ranking Model tackles a critical challenge in serving large language model (LLM)-scale recommendation systems for ads: balancing massive model complexity with sub-second latency and cost efficiency. This Q&A explores the technology behind it, including the inference trilemma, intelligent request routing, and key innovations that bend the scaling curve.
What is the inference trilemma in LLM-scale ad serving?
The inference trilemma refers to the tension among three competing demands: model complexity, low latency, and cost efficiency. As Meta scales its recommendation models to LLM-scale (hundreds of billions of parameters), the naive approach of using a single massive model for every request would break sub-second latency requirements and inflate infrastructure costs. The trilemma forces engineers to choose between sacrificing model depth (hurting ad relevance), increasing latency (hurting user experience), or ramping up compute spend (hurting ROI). Meta's Adaptive Ranking Model resolves this by dynamically assigning model complexity per request instead of using a one-size-fits-all inference pipeline.

How does Adaptive Ranking Model bend the inference scaling curve?
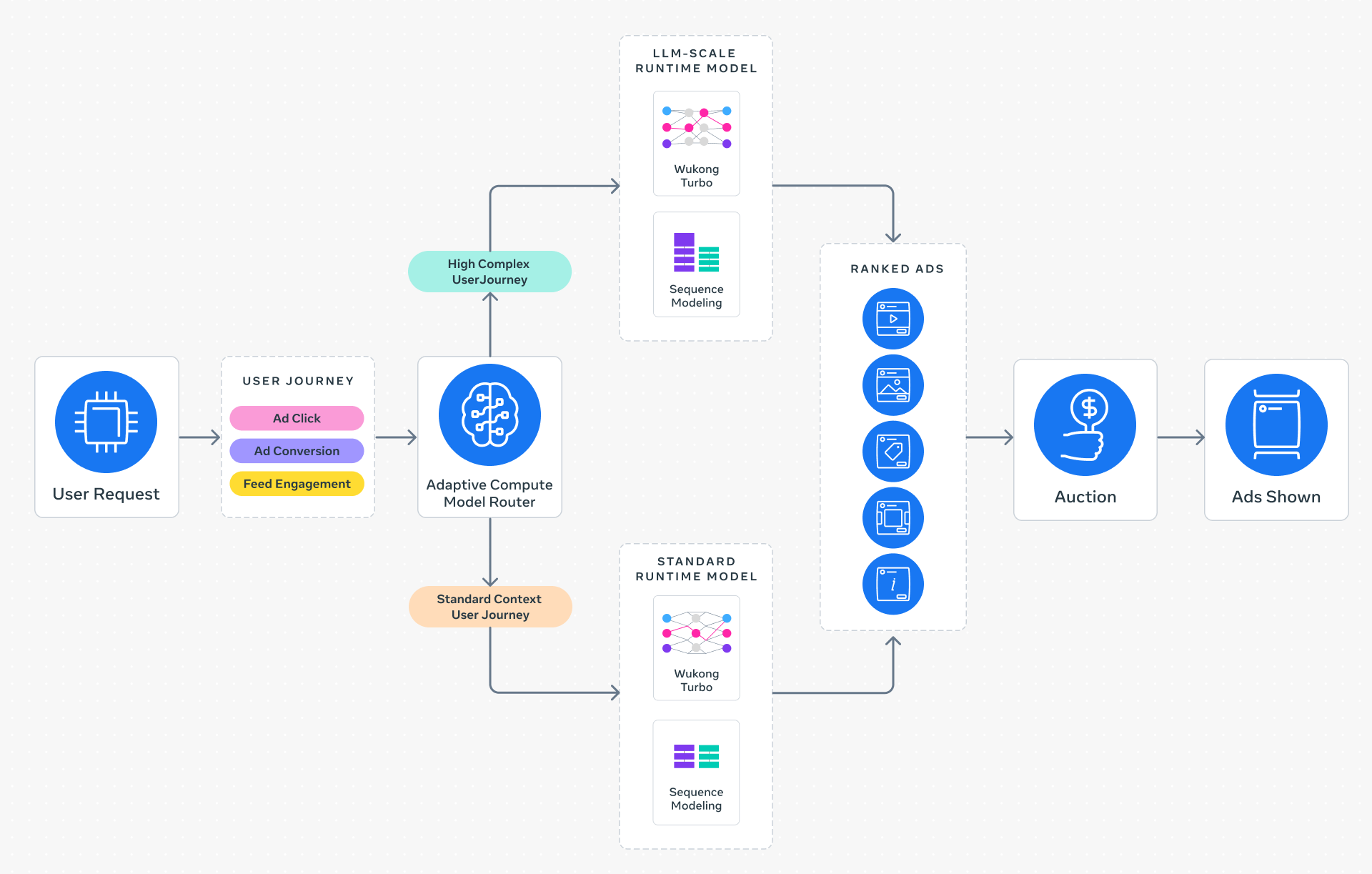
Instead of deploying a static, monolithic model for all ad requests, Adaptive Ranking Model employs intelligent request routing. It analyzes each user's context, historical behavior, and inferred intent to select the most appropriate model tier—ranging from lightweight models for simple queries to full LLM-scale models for complex, high-value opportunities. This dynamic alignment ensures that only necessary compute is used, effectively "bending" the inference scaling curve. The result is that Meta serves LLM-scale models at sub-second latency while keeping marginal cost per inference low, achieving a high return on investment (ROI). The system adapts in real-time, making it possible to handle billions of daily requests without latency spikes.
What are the three key innovations behind this system?
Meta introduced three core innovations to make LLM-scale ad serving practical:
1. Inference-Efficient Model Scaling – A shift from a model-centric to a request-centric architecture. Instead of processing all requests through the same heavy pipeline, the system selects a tailored sub-network or ranks candidates using a distilled large model, drastically reducing compute per request.
2. Model/System Co-Design – Hardware-aware model architectures that align neural network design with the capabilities and limitations of Meta's heterogeneous silicon (e.g., custom AI accelerators, GPUs). This improves hardware utilization and avoids memory bottlenecks.
3. Reimagined Serving Infrastructure – Multi-card parallelism and hardware-specific optimizations (e.g., tensor slicing, mixed-precision inference) enable serving models with O(1 trillion) parameters in production, previously thought impossible for real-time ads.
How does the system understand user context and intent dynamically?
At the start of each ad request, Adaptive Ranking Model evaluates a rich fingerprint of the user: recent clicks, search history, time of day, device type, session length, and implicit signals like dwell time. This fingerprint is fed into a lightweight context encoder—a small transformer—that produces an intent embedding. The embedding is then used to query a routing table, which maps similar intents to the most effective model tier. The routing is continuously updated via online learning (bandit-style exploration), so the system improves over time. This ensures that, for instance, a casual browser sees a fast shallow model, while a power user likely to convert receives the full LLM-rank with deep personalization.
What performance gains has Adaptive Ranking Model delivered on Instagram?
Since launching on Instagram in Q4 2025, the system showed a +3% increase in ad conversions and a +5% increase in ad click-through rate (CTR) for targeted users. These metrics are particularly impressive because they come without increasing overall system latency or cost—in fact, computational efficiency improved due to the smart routing. For advertisers, these lifts translate directly into better ROI: more conversions per dollar spent. Meta also reports that the model maintained sub-second p99 latency even with LLM-scale complexity, a benchmark that competing platforms have struggled to achieve. The gains are expected to grow as the routing policy learns from more traffic.
How does this compare to traditional recommendation systems?
Traditional recommendation systems (e.g., Facebook's older models or Amazon's item-to-item) rely on a fixed deep neural network or matrix factorization, trained offline and served uniformly. Those models hit an accuracy plateau because they cannot afford the compute of LLM-scale architectures for every request. Meta's Adaptive Ranking Model breaks that plateau by varying inference cost per request. While a traditional system might serve 100 million requests daily with a 100-million-parameter model, Meta can now serve 10 million requests with a 1-trillion-parameter model and 90 million with smaller variants, achieving far better aggregate performance. This hybrid approach is more efficient than broadcasting the same heavy compute to all users.
What does this mean for the future of AI in advertising?
Meta's work signals a paradigm shift: the next frontier in advertising will be context-aware model selection rather than simply scaling up a single model. We can expect other platforms (Google, TikTok, Amazon) to adopt similar adaptive inference techniques to bridge the gap between research-scale LLMs and real-time production. For advertisers, this means higher relevance and better performance without paying for wasted compute. For users, it means faster, less intrusive ads that align with their current intent. Eventually, this technology could extend beyond ads to feeds, search, and recommendations across the web.
Related Articles
- OpenAI’s Future at Stake: Inside the Musk-Altman Courtroom Clash
- Mastering OpenAI’s GPT-5.5 Instant: A Practical Guide to Smarter, More Reliable ChatGPT Responses
- LLM Feature Toggles Create 'Opt-In Trap' That Biases Product Metrics, New Analysis Shows
- 7 Key Features of GPT-5.5 in Microsoft Foundry for Enterprise AI
- 7 Ways Docker’s Virtual Agent Fleet Revolutionizes CI/CD and Testing
- Achieving Persistent Agentic Memory Across AI Coding Assistants with Hook-Based Neo4j Integration
- AWS Unveils Major AI-Driven Updates: Amazon Quick Desktop App, Expanded Connect Suite, and OpenAI Collaboration
- AI Agents with LLM 'Brains' Revolutionize Problem Solving: Experts Warn of Rapid Advances