7 Key Takeaways from Kubernetes v1.36's PSI Metrics Graduation to GA
With Kubernetes v1.36, Pressure Stall Information (PSI) metrics have officially graduated to General Availability (GA), providing a stable and production-ready interface for observing resource contention at the node, pod, and container levels. While traditional utilization metrics only show usage percentages, PSI reveals the real cost of resource saturation—time lost when tasks stall waiting for CPU, memory, or I/O. This listicle dives into seven essential insights from the graduation, including the performance testing that proved its readiness for scaling across high-density workloads.
1. Why PSI Matters More Than Traditional Utilization
Relying solely on CPU or memory utilization percentages can be dangerously misleading. A node might show only 70% CPU usage while critical tasks experience severe latency due to scheduling delays. PSI fills this blind spot by measuring how often tasks are stalled—what percentage of time they spend waiting for resources. Unlike utilization, PSI captures the user experience of resource contention. For example, a high PSI value on CPU means processes are waiting for CPU time, even if the utilization isn't maxed out. This distinction is crucial for preventing outages: by detecting resource pressure early, operators can take action before a problem fully materializes. PSI provides a more accurate, high-fidelity signal for capacity planning and troubleshooting.
2. The Key Metrics: Cumulative Totals and Moving Averages
PSI exposes two primary metric types that together give a complete picture of resource contention. First, cumulative totals represent the absolute amount of time (in microseconds) that tasks have been stalled. This running count lets you calculate pressure over any arbitrary period. Second, moving averages smooth out noise with windows of 10 seconds, 60 seconds, and 300 seconds. The 10-second average catches transient spikes that might hint at imminent problems, while the 300-second average reveals sustained, longer-term tension. Operators use these together to distinguish between a harmless burst (e.g., a short batch job) and an evolving capacity bottleneck. This dual view is the reason PSI is more actionable than raw utilization alone.
3. How PSI Works at the Kernel Level
PSI was first implemented in the Linux kernel in 2018. It works by tracking the time tasks spend in an uninterruptible sleep (for I/O) or in a runnable but waiting state (for CPU). The kernel collects this information at the cgroup level, making it available per-container in Kubernetes. To expose PSI in Kubernetes, the kubelet reads the kernel's pressure files (e.g., /proc/pressure/cpu) and exposes them as metrics through the Metrics API. This pipeline is lightweight because the kernel already tracks PSI by default (when psi=1 is set). The kubelet simply reads pre-computed values. Performance validation confirmed that enabling the KubeletPSI feature gate adds negligible overhead—less than 0.1 cores on a 4-core machine—making it safe for production clusters.
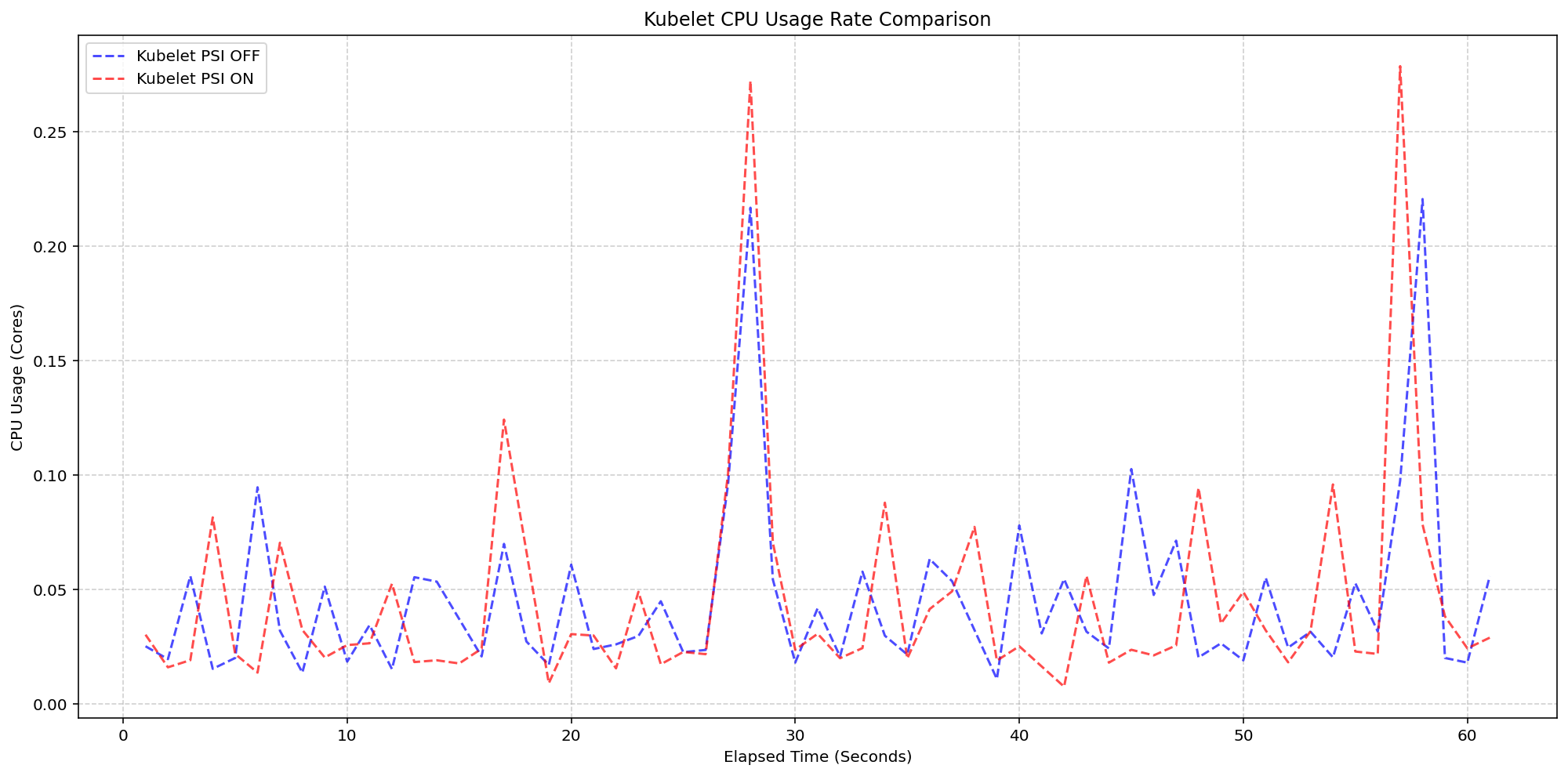
4. Kubelet Overhead: Negligible Impact on Production
A major concern for any new telemetry feature is the resource cost of collection. SIG Node designed a rigorous test: on 4-core machines with 80+ pods, they compared clusters where the kubelet PSI collection was enabled versus disabled (both with kernel PSI already on). The results showed that the kubelet's CPU usage was nearly identical in both cases—practically overlapping in bursts. The active collection of PSI metrics consumed only about 0.1 cores, or 2.5% of total node capacity. This confirms that the kubelet's PSI gathering logic is extremely lightweight and integrates seamlessly into the existing housekeeping cycle. Operators can enable the feature without worrying about measurable performance degradation, even under high pod density.
5. Kernel Overhead: Minimal and Predictable
Beyond the kubelet, there was concern about the kernel-level overhead when PSI tracking is turned on. In a second scenario, the team compared clusters with kernel PSI off versus on (both with the kubelet feature active). The system CPU usage (kernel time) showed a slight increase—around 2.5 cores total for the node—but the pattern remained consistent with the baseline. The additional cost is due to the kernel updating pressure statistics continuously. However, because this work is done during existing context switches and scheduler ticks, the overhead is bounded and predictable. For most workloads, the benefit of having real-time pressure signals far outweighs this minor uptick in system CPU. The tests confirm that enabling kernel PSI is a safe choice for production deployments.
6. Validated on High-Density Workloads (80+ Pods)
To prove production readiness, the performance testing was conducted on high-density clusters with over 80 pods per node, across different machine types (including 4-core, 8-core, and 16-core instances). The tests simulated realistic contention scenarios, such as CPU-bound and I/O-bound applications, to ensure PSI metrics behaved correctly under stress. The results showed no degradation in the kubelet's response times or metric accuracy. PSI metrics remained consistent even when the node was under heavy pressure, showing that the graduation process thoroughly vetted the feature's scalability. This gives operators confidence that PSI will work reliably in environments with dense pod packing, such as those found in cloud-native platforms and large-scale microservices deployments.
7. What This Means for Kubernetes Operators
With PSI now GA in Kubernetes v1.36, operators have a stable and official API to expose resource pressure. This enables better autoscaling decisions (e.g., using PSI as a metric for HPA), faster troubleshooting by correlating latency with pressure events, and proactive capacity planning. The low overhead means it can be enabled cluster-wide by default, without special tuning. As a best practice, operators should start by enabling the KubeletPSI feature gate and monitoring the pressure metrics alongside traditional utilization. Tools like Prometheus can scrape these metrics and alert on crossing thresholds (e.g., CPU average over 70% for 5 minutes). The graduation to GA marks a significant step toward making resource contention observability a first-class citizen in Kubernetes.
Conclusion
The graduation of PSI metrics to GA in Kubernetes v1.36 arms the ecosystem with a robust mechanism to detect resource saturation before it becomes an outage. By moving beyond traditional utilization and focusing on stalled task time, PSI gives operators a truer picture of node and container health. The performance testing, which confirmed negligible overhead from both the kubelet and kernel, ensures that this feature is safe for production, even on dense workloads. For anyone managing Kubernetes at scale, enabling PSI is a low-cost, high-value step toward more resilient infrastructure.
Related Articles
- 6 Essential Insights into Thunderbolt: Mozilla's Open-Source AI Client for Enterprises
- Empower Your Development with Squad: An AI Agent Team for Coders
- Strawberry Music Player Reaches New Milestone: A Full-Featured Linux Music Management Solution
- Fedora KDE Plasma Desktop 44: A Polished Fusion of Performance and Personalization
- Fedora Embraces AI: 10 Key Points About the New AI Developer Desktop Initiative
- Firefox’s Free VPN Expands: Users Can Now Choose Server Location – Major Privacy Upgrade
- Reimagining Unity: A Modern Take on Ubuntu's Classic Desktop
- Fedora KDE Plasma Desktop 44 Launches with Plasma 6.6 and Major Usability Upgrades