DIY Innovator Turns Raspberry Pi into Portable AI Server: Power Bank-Powered Linux Box Runs LLMs Anywhere
Breaking: Pocket-Sized Linux Server Now Runs Advanced Language Models on Battery Power
A developer has transformed a Raspberry Pi into a pocket-sized Linux server that operates solely from a standard power bank, achieving remarkable performance in running lightweight large language models (LLMs). The project demonstrates that ARM-based single-board computers can serve as portable AI inference engines, challenging assumptions about hardware requirements for machine learning.

Early tests show the system can handle sub-4B parameter models with surprising efficiency, and when clustered, can even manage 9B models—albeit with significantly reduced token generation speeds. This breakthrough opens new possibilities for field deployments, edge computing, and privacy-preserving AI applications where cloud connectivity is unavailable or undesirable.
Background: ARM Boards Gain Ground in DIY AI
Raspberry Pi devices have long been used for light server tasks, but running LLMs was considered impractical due to limited RAM and processing power. Recent optimizations in model quantization and efficient inference frameworks have changed the landscape, making it feasible to run small models on ARM-based SBCs.
The project builds on a growing trend of using low-power devices for local AI tasks. “Many x86 PCs are tied up in other projects, so I turned to ARM boards,” explains the developer, who requested anonymity. “I was surprised at how well they handle lightweight models.”
Details: How It Works
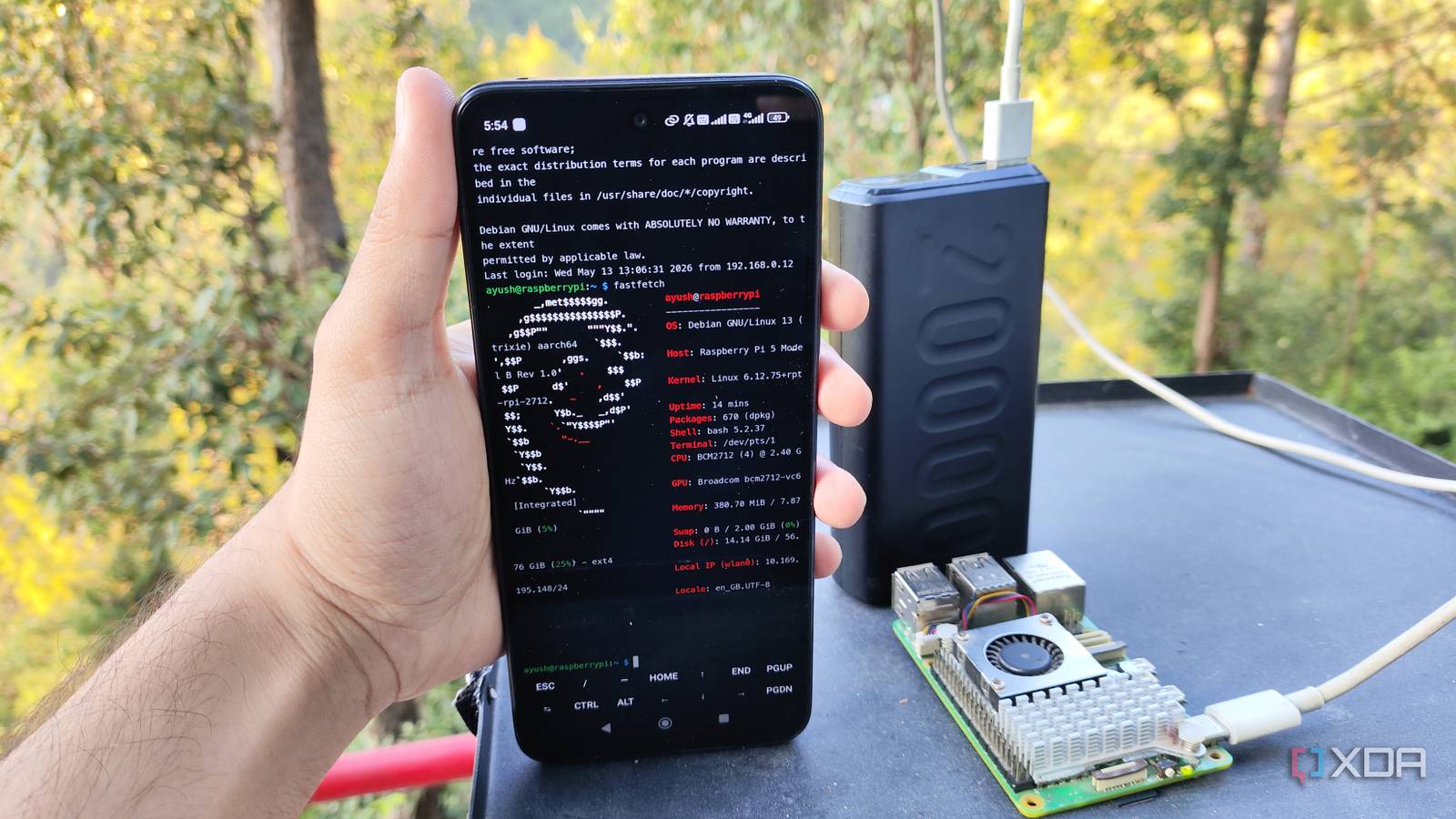
The pocket server uses a Raspberry Pi 5 running a stripped-down Linux distribution optimized for low power consumption. The entire system draws less than 10 watts and connects via USB-C to a standard power bank, making it truly portable.
Software includes the llama.cpp inference engine with custom scripts to load and run quantized models from an external SSD. The developer reports that sub-4B models (such as TinyLlama and Phi-2) run at usable speeds for text generation, while larger 9B models require multiple Pis in a cluster—achieving throughput in the range of 1-3 tokens per second.
Expert Reactions
Dr. Elena Marchetti, a researcher in edge AI at MIT, comments: “This demonstrates the surprising capability of affordable hardware. For applications like on-device translation or summarization in remote areas, such a setup could be game-changing.”
However, she cautions: “Token rates for larger models are still too slow for interactive use. But for batch processing or latency-insensitive tasks, it’s perfectly viable.”
What This Means: Portable AI Becomes Reality
This breakthrough means that any place with a power bank can now host a private, offline AI assistant. It reduces reliance on cloud services, cuts costs, and enhances data security—important for healthcare, journalism, and fieldwork.
While not a replacement for datacenter-grade hardware, the pocket server fills a niche for always-available, low-footprint AI. As ARM optimizations continue, future models may achieve higher performance, making this approach mainstream for developers and enthusiasts.
For a deeper dive into the technical setup, see the related Background section or explore how it works.
Related Articles
- How to Let Your Coding Agent Automatically Set Up Cloudflare and Deploy Your App
- State Preschool Funding Hits Record Highs, but Quality Gaps Persist Across the Nation
- Nebius Stock Surges on AI Revenue Growth: Key Q&A
- Apple App Store Harbors Dozens of Phishing Apps Stealing Crypto Wallet Keys
- Java Ecosystem Update: JDK 26 Reflections, Spring AI 2.0, and the Vibe Coding Debate
- Apple Subpoenaed Over Vehicle Modding App: Key Questions Answered
- Navigating the Shift to Post-Quantum Cryptography: A Practical Migration Guide for Organizations
- Crypto Dips as Stock Market Soars: Iran Peace Optimism Sparks Divergent Trends