7 Key Insights on the GA of PSI Metrics in Kubernetes v1.36
Pressure Stall Information (PSI) has long been a hidden gem in the Linux kernel, offering deep visibility into resource contention before it escalates into a full-blown outage. With Kubernetes v1.36, PSI metrics graduate to General Availability (GA), providing a stable, production-ready interface for monitoring CPU, memory, and I/O pressure at the node, pod, and container levels. This milestone marks a significant step forward in cluster observability, but it also raises important questions about overhead, reliability, and how to best leverage these new signals. In this article, we break down the seven most critical insights from this graduation, from the underlying kernel technology to the rigorous performance testing that proved its readiness.
1. PSI Metrics: A New Standard for Node Health
PSI metrics, introduced in the Linux kernel in 2018, capture the percentage of time tasks spend waiting for resources like CPU, memory, and I/O. Unlike traditional metrics that report resource usage (e.g., 80% CPU utilization), PSI directly measures stall — time lost due to contention. In Kubernetes v1.36, these metrics are now exposed as a GA feature, meaning they are stable, backward-compatible, and ready for production use. This graduation allows cluster operators to set up reliable alerts and dashboards based on stall percentages, enabling early detection of resource saturation. The move to GA also standardizes the metric format across nodes, making cross-cluster comparisons more consistent.
2. Beyond CPU and Memory: Understanding Resource Contention
Traditional utilization metrics can be deceptive. A node may show only 70% CPU usage, yet tasks suffer severe latency due to scheduling delays or I/O waits. PSI fills this gap by providing cumulative totals (absolute stalled time) and moving averages over 10s, 60s, and 300s windows. These moving averages help operators distinguish between transient spikes and sustained pressure. For instance, a short spike in memory pressure might be harmless, but a rising 300s average signals a systemic issue. This context is critical for capacity planning, autoscaling decisions, and root cause analysis. PSI gives you the why behind performance degradation — not just the what.
3. Kernel-Level PSI: The Foundation
PSI data originates in the Linux kernel, which tracks pressure at the cgroup level. Enabling PSI requires the kernel boot parameter psi=1 (default on most modern distributions). The kernel continuously samples task scheduling and I/O operations to calculate stalled time percentages. This data is then exposed through files in /proc/pressure/ for CPU, memory, and I/O, as well as per-cgroup pressure files. Kubernetes v1.36’s GA feature relies on this kernel foundation, reading those cgroup metrics and surfacing them via the Kubelet’s metrics endpoint. Without kernel PSI enabled, the Kubernetes feature cannot function; thus, it is a prerequisite for any cluster adopting this capability.
4. Kubelet's Role in Exposing PSI Data
The Kubelet is the node agent responsible for collecting and exposing PSI metrics. With v1.36, the KubeletPSI feature gate is enabled by default (as part of GA). The Kubelet periodically reads per-cgroup pressure files from the kernel and translates them into Prometheus-format metrics. These metrics are then available through the /metrics/resource/v1alpha1 endpoint, which can be scraped by monitoring tools like Prometheus. The Kubelet processes only the cgroups corresponding to pods and containers, not all system cgroups, ensuring efficiency. Importantly, the overhead of this collection is negligible, as confirmed by performance testing (see items 5 and 6). This design makes PSI data accessible without manual kernel coding.
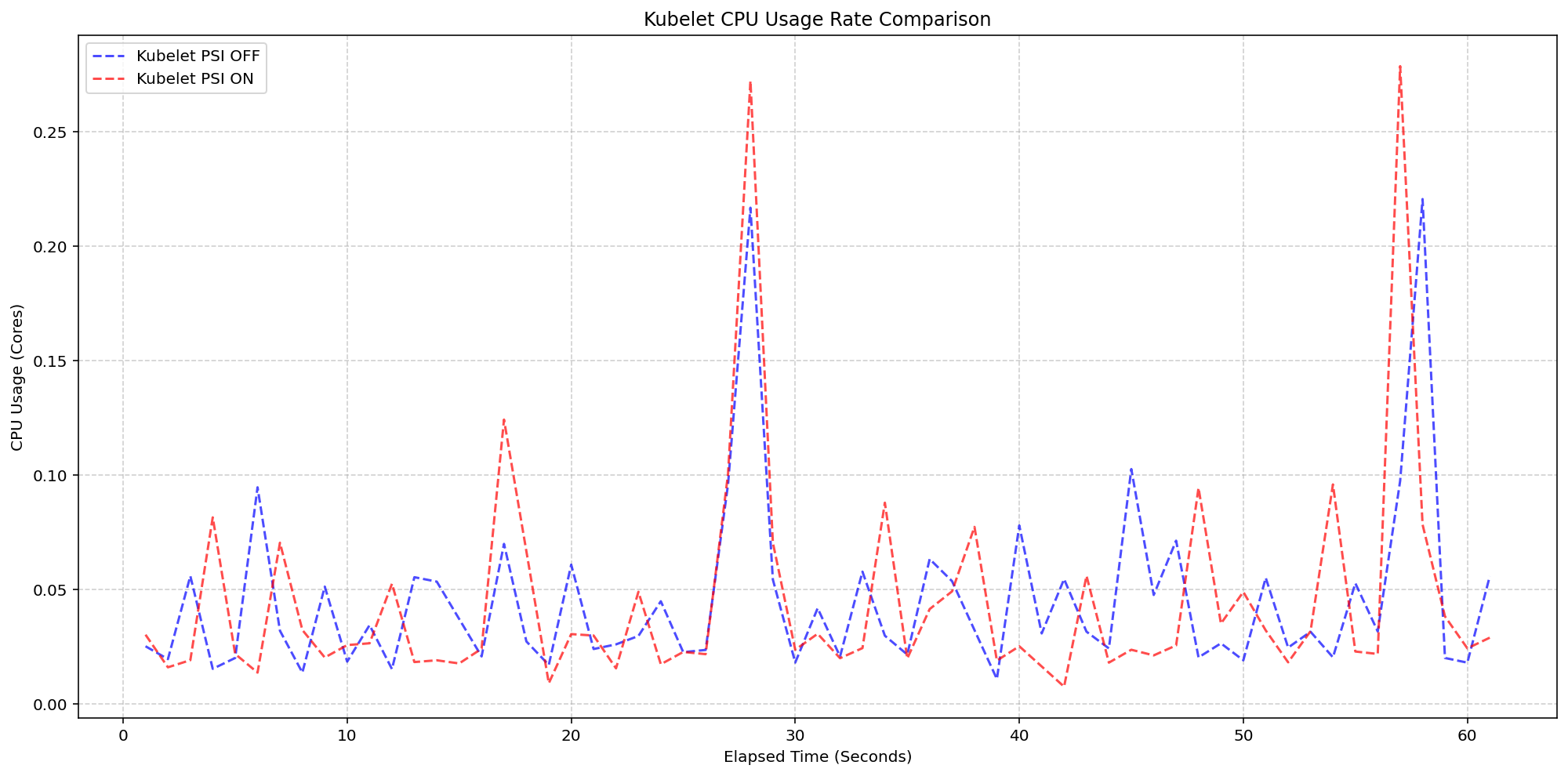
5. Rigorous Performance Testing: Kubelet Overhead
A primary concern for any new telemetry feature is the resource cost of collecting and serving the data. SIG Node conducted extensive tests on high-density workloads (80+ pods per node) across various machine types. The first scenario compared Kubelet CPU usage with kernel PSI enabled but KubeletPSI feature off versus on. Results showed that the Kubelet’s CPU usage was nearly identical in both cases — typically less than 0.1 cores (2.5% of a 4-core node). The synchronized bursts in usage plots confirmed that the Kubelet’s collection logic is lightweight and merged into existing housekeeping cycles. This means enabling PSI does not introduce additional CPU spikes or latency, making it safe for production.
6. Kernel Overhead: Minimal Impact Confirmed
The second performance scenario tested kernel overhead by comparing a cluster with kernel PSI off (and KubeletPSI on) versus kernel PSI on (and KubeletPSI on). The system CPU usage lines for the two clusters followed the same pattern, with a slight expected increase (around 2.5 cores of system CPU) when kernel PSI was active. This increase is attributable to the kernel’s ongoing pressure tracking, not the Kubelet’s read operations. Since most modern Linux kernels have PSI enabled by default, this overhead is already present on most nodes. Therefore, activating the Kubernetes feature does not add extra kernel load. The measured overhead falls well within acceptable limits for production clusters, even under high pod density.
7. What GA Means for Kubernetes Users
The graduation of PSI metrics to GA in Kubernetes v1.36 provides a stable, reliable interface for monitoring resource contention. Users can now confidently use these metrics in production alerting, dashboards, and autoscaling policies without fear of breaking changes. The feature’s minimal overhead has been validated across multiple scenarios, and the data model (cumulative totals plus moving averages) aligns with best practices for time-series monitoring. For cluster administrators, this means earlier detection of resource pressure, reduced reliance on reactive troubleshooting, and more informed capacity decisions. Operators upgrading to v1.36 should verify kernel PSI is enabled and consider adding PSI-based thresholds to their monitoring stacks.
In summary, the GA of PSI metrics in Kubernetes v1.36 is a milestone that brings powerful diagnostics to everyday cluster operations. By understanding the seven insights above — from kernel foundations to performance validation — you can fully leverage PSI to improve resource management and prevent outages. Whether you’re fine-tuning auto-scaling policies or investigating performance anomalies, PSI metrics offer a clear, low-overhead view into the pressure points of your clusters. Upgrade to v1.36 and start exploring this new observability superpower today.
Related Articles
- Linux Distros Officially Adopt Standard 'Projects' Folder; Ubuntu Leads AI Push with Local Models
- 6 Key Highlights of Fedora Asahi Remix 44
- Meta's AI-Powered Efficiency: How Unified Agents Scale Performance Optimization
- How to Transition to Fedora Linux 44 Atomic Desktops: A Step-by-Step Guide
- Everything You Need to Know About the Framework Laptop 13 Pro and Ubuntu Certification
- Linux Kernel 7.1: A Deep Dive into New NTFS Driver, Expanded Hardware Support, and Performance Tuning
- Meta's KernelEvolve: Autonomous Kernel Optimization for Scalable AI Infrastructure
- Upgrading to Fedora 44: A Complete Guide for Atomic Desktop Users